Diffusion Processes
A brief summary of diffusion models
Introduction
Last year’s 42nd International Conference on Machine Learning (ICML) in Vancouver, BC, was my first conference in a few years and at the conference were a lot of interesting papers on diffusion processes. Prior to attending, I wasn’t following research on this topic but have since taken a liking to it and so in this post, I’ll briefly outline what diffusion models are, their component processes and training.
What is Diffusion?
Diffusion is simply a generative modelling technique that generates data from random noise in a finite series of steps. It entails transforming data into random noise and then learning the reverse transformation in order to regenerate the data. The noise transformation process is referred to as the forward process and the generation process is referred to as the reverse process.
Forward Process
The forward diffusion process transforms data into random noise. However instead of doing this in a single or a few steps, it is done over many timesteps by perturbing the data with a small amount of zero-mean Gaussian noise. This is a lot more tractable than adding a single noise that destroys the data and bears some resemblance to non-equilibrium statistical processes in physics (Sohl-Dickstein et al., 2015).
We can express the transformation between adjacent timesteps as
where beta is the variance parameter that controls the amount of noise or rate of diffusion at a particular timestep. Initially we start off with a very small rate but steadily increase it at each timestep such that
Starting from the initial data, we can express the data at any given time in the forward process as
This weighted additive noise process can also be seen as sampling the data from a Gaussian distribution that is conditioned on the initial data
To facilitate learning, we run the forward process for a given data over many iterations and then use the data at each timestep to train the diffusion model in the reverse process.
Reverse Process
As it suggests, in the reverse process the diffusion model learns to remove noise that was added during the forward process. Unlike the forward process where data is assumed to be sequential, in the reverse process it is treated as identical and independent. This lack of prior information however makes denoising the data at any timestep infeasible.
The task becomes feasible when information about the initial data is we included. In doing so we can sample the denoised image from the following posterior distribution
where
and
Although the initial data is available during training, it is unavailable during testing. To denoise the current data, we use an approximation to the initial data that is learned during training. This learned approximation can come from function approximators like neural networks. The network can be seen as a denoising auto-encoder that attempts to generate the original data from its noisy versions. This works pretty well and generates true samples of the data distribution rather than just the mean of the distribution.
The denoising diffusioin model by (Ho et al., 2020) goes one step further. It reformulates the posterior mean above in terms of the current data and noise added. Rather than estimate the initial data, it estimates the noise itself and removes it from the current data. This is a lot harder to do as it requires more powerful neural network architectures that are able to capture the noise.
Training Objective
Diffusion models optimize the Evidence Lower Bound (ELBO) objective (Weng, 2021)
To maximize this lower bound, we can express the Kubler-Libler divergence as
where we have a divergence between the reverse probability and the learned probability across the diffusion timesteps. Since we have the analytical form of the reverse probability, this KL divergence reduces to a squared loss regression between the mean of learned probability and that of the reverse probability
Depending on how we choose to parameterize the mean, either as the initial data or noise, we end up with two different objective functions where the target is the initial data or current noise from the forward process and the regressor is the network output.
Examples
To illustrate the capability of diffusion models, we can use two relatively simple datasets: Swiss Roll and the MNIST dataset. In both examples, the diffusion model learns to predict the initial data during training and uses an approximation of this data to generate the samples shown.
Swiss Roll
The SwissRoll dataset is a well known dataset for dimensional embedding. It consists of points that form a 3D swiss roll with different color gradients. For our example, we simply take the 2 dimensions that best illustrate the swiss roll structure as shown below

For this dataset, the network is a MultiLayer Perceptron (MLP) with a radial basis function hidden layer and 2 separate linear outputs. I used a variance between 0.001 and 0.05 for 40 diffusion steps. The model was trained with 100 points per batch for 1500 epochs. The image below illustrates the reverse process for a few sampled digits
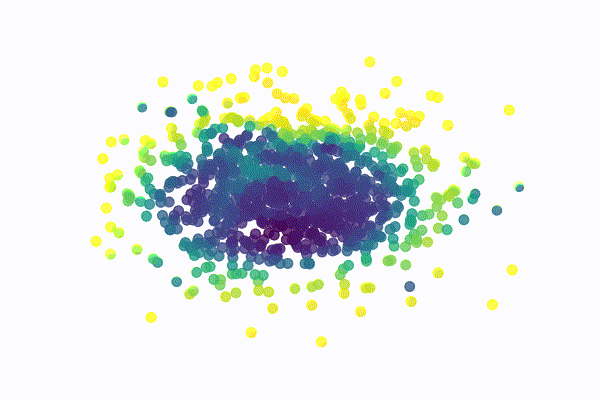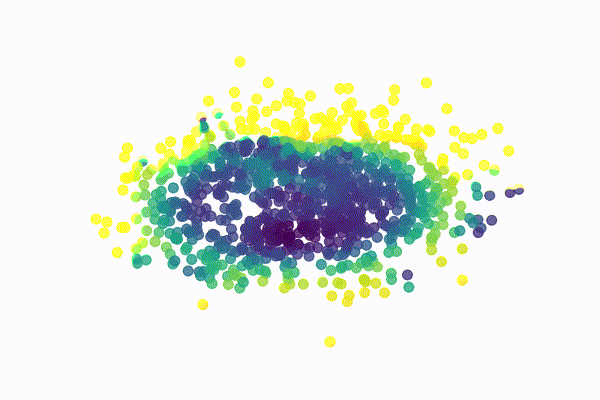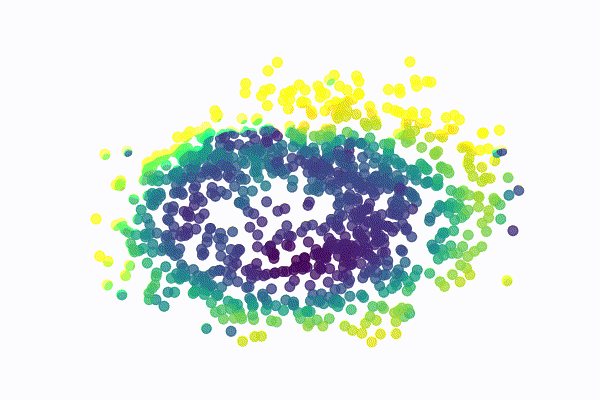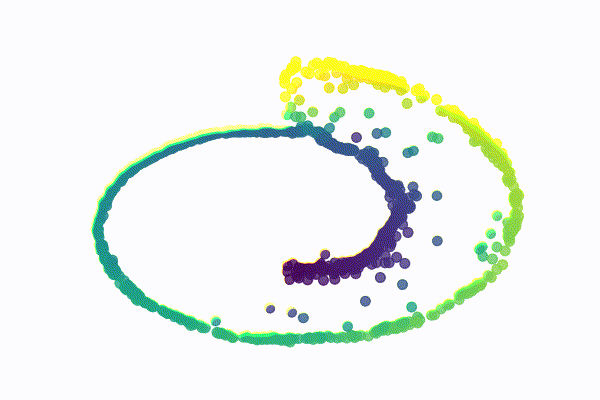
MNIST
The MNIST dataset is a popular machine learning image dataset comprising of 28 x 28 greyscaled handwritten digits numbered 0 to 9.
For this dataset, the network used is a U-Net with ShuffleNet units and a multilayer perceptron (MLP) for embedding each timestep. There were 1000 diffusion timesteps with a variance between 0.0001 and 0.02. The model was trained for 10 epochs with a batch size of 128. The image below illustrates the reverse process for a few sampled digits

- Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., & Ganguli, S. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. International Conference on Machine Learning, 2256–2265.
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33, 6840–6851.
- Weng, L. (2021). What are diffusion models? Lilianweng.github.io. https://lilianweng.github.io/posts/2021-07-11-diffusion-models/